
After a few years of plodding along the hackerspace / shadetree engineering path, I have encountered the same problem multiple times in multiple forms. Once in a while, you need to translate an object which exists in the real world, into the digital world.
Let's say you need a 3D model of the members of your band for a cool video.
In the old days, this was a tedious and manual process, to digitize anything, lacking any pre-existing tools that could easily facilitate the project. Take Rebecca Allen, for example. She worked for TWO YEARS to create the above 1986 Kraftwerk video. Here she is pictured with a reference model of drummer Karl Bartos, plotting each point by hand with a digitizer, using homebrew software.

In 1982, it was even HARDER to digitize objects. Remember Tron?
The Evans and Sutherland Picture System 2, which was used to render Tron, had a whopping 2 Megabytes of RAM, and 330 Mb of disk space. A large percentage of the effects in this film were actually Rotoscoped by hand, rather than using a computer to add visual effects.
Today, you can buy a Google Tango tablet, designed specifically for 3D imaging, with 4 Gb of RAM, a flamethrowing nVidia processor, all sorts of bells and whistles, for ~$500. Put in relative terms, an iPad2 has equivalent GFLOP processing power of the most powerful Cray supercomputer from 30 years ago.

You carry this around in your bag, like it's no big deal, and use it mostly for Flappy Bird.
But I digress.
The point I'm trying to make, is that we are now carrying enough processing power around in our pockets to be able to accomplish sophisticated 3D imaging, which was previously computationally prohibitive.
Beyond the absurd availability of computational power today, lots of research has been performed in the last 30 years in the field of computer simulation, ray tracing, and other relevant algorithms. All this research adds together to allow this deluge of computer power to be specifically focused on the task at hand, in this case 3D imaging and reconstruction.
In previous blog posts, we covered a low-cost scanning technique using the Microsoft Kinect sensor. Initially not intended for use as a 3D scanner, massive development of the Kinect ecosystem by Microsoft and others has created a wake of alternative uses for the Kinect hardware.
One challenge with scanning using the Kinect is the trade-off between scan volume and resolution. The Kinect is capable of scanning physical space ranging from 0.5 to 8 meters in size. Instead of pixels as you would have in a 2D environment, the Kinect tracks "voxels" in a 3D environment, in an array of roughly 600 x 600 x 600 elements. In the highest quality settings, this makes for an minimum tolerance of +/- 1 mm of error, about 1% overall, in the resulting scan data. This is great resolution when scanning items about the size of a shoe box, 0.5 m^3, but sometimes you want to scan larger objects that the Kinect would struggle to visualize with high enough resolution.
What about scanning objects smaller than 0.5 m^3? The Kinect has a miminum scanning distance of ~600 mm, and has a difficult time visualizing small features on small parts.
Using photogrammetry (specifically, stereophotogrammetry), all you need is an array of photographs from different angles of the same scene, and a properly configured software stack.
There are a few photogrammetry solutions on the market ranging from free to very expensive. Most of these softwares essentially do the same thing, the main distinction being that 123DCatch performs remote processing on the cloud, where CapturingReality performs the required calculations locally. Due to this fact, your choice of software boils down to what quality of hardware you're using.
Using photogrammetry (specifically, stereophotogrammetry), all you need is an array of photographs from different angles of the same scene, and a properly configured software stack.
There are a few photogrammetry solutions on the market ranging from free to very expensive. Most of these softwares essentially do the same thing, the main distinction being that 123DCatch performs remote processing on the cloud, where CapturingReality performs the required calculations locally. Due to this fact, your choice of software boils down to what quality of hardware you're using.
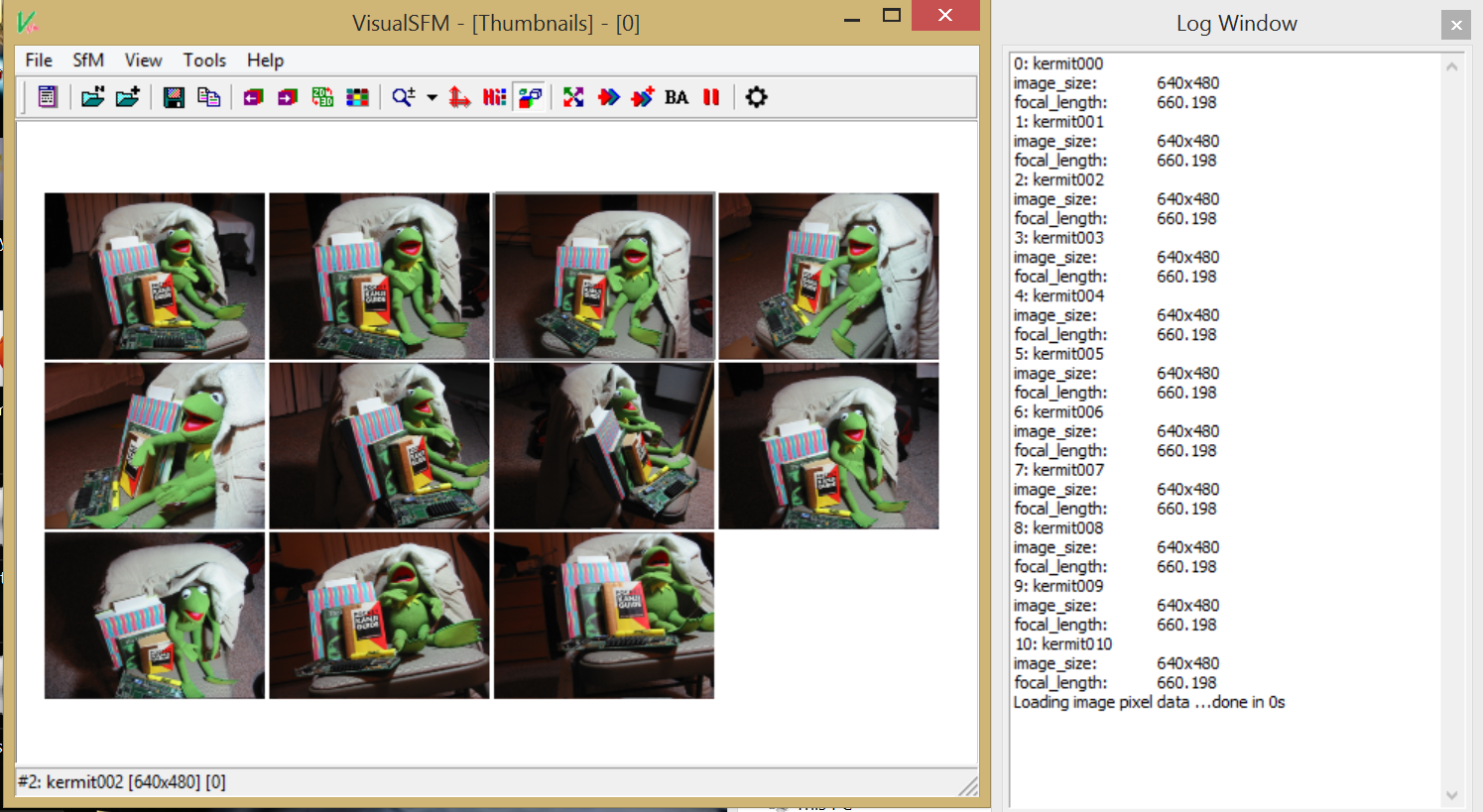
My toolchain of choice for this process is twofold: VisualSFM and Meshlab. Both of these tools are free, mostly open-source*, and quite robust once you know how to coax the proper filtered data out. The main benefit of this toolchain is that they're freely available for Linux / Mac / Windows. It can even be done without CUDA cores, although it seems that some optimization for the process is achieved with using CUDA architecture GPUs
VisualSFM is used to sort an array of images, and apply the SIFT algorithm for feature detection on each image. This processes each image using the Difference of Gaussians, one method for computerized feature recognition, along with a comparison between each frame. The software is then able to infer a relative position and orientation for each camera.


Meshlab is
used to perform a mathematical reconstruction of the VisualSFM output.
VisualSFM outputs a cartesian point cloud, and it's your job as the
creative human to make sense of that data (turns out 3 Dimensional matching has been proven to be NP-hard).
A point cloud by itself isn't
inherently useful. With Meshlab, we perform a conversion of the noisy
point cloud to a high quality, watertight triangular mesh which can then be used in all sorts of applications like reverse engineering, 3D printing, VR and AR, computer vision, et cetera.

We first perform a Poisson surface reconstruction to create a solid, triangular-faceted surface with a high quality alignment to the original point cloud. The resulting mesh can tend to be noisy, so a few filtering algorithms are applied to smooth the surfaces and edges and clean the outliers. Essentially, all you're doing is noise filtering.

Mesh size is of crucial importance for computability. Sometimes the meshes reconstruct with millions of faces, which can be challenging to process on anything but modern gaming rigs with giant GPUs. Furthermore, our resulting reconstruction is rough, aesthetically approximating a surface, rather than being a 99% dimensionally accurate representation of the surface. Such a high quality of reconstruction is approachable using strictly photogrammetric or structured light techniques, but probably better suited to Time-of-Flight laser scanning techniques like that of the NextEngine. TOF scanners can achieve micron-scale resolution, unlike triangulation scanners like the Kinect.
Do we need to reconstruct a scene in a video game, requiring a low quality model with a high quality, registered texture? Do we need to recreate a shape with a high dimensional accuracy, with no consideration to texture or color? Photogrammetry can accomplish both, but is better at the former.
Meshlab is used to robustly modify the reconstructed mesh surface with mathematical processes (you should probably also look at Meshmixer). Some of the more challenging, opaque problems can hide deep within the mesh, like a single non-manifold vertex which may never appear in the visual rendering. This can be solved with a quick selection filter, and deleting the offending geometry. "Quadric Edge Collapse Decimation" is used to reduce the polygon count of the resulting surface. My favorite filter lately has been "Parameterize and texturize from registered rasters" which creates an awesome texture map with VisualSFM output.
Once you have the clean, reconstructed surface, save the file somewhere memorable. VisualSFM has an output file called "bundle.rd.out" which is a sparse reconstruction of the surface, along with "list.txt" which is the list of registered raster images we're going to use to apply color to the reconstructed surface. By importing the reconstructed surface into this new workspace, we can superimpose the aligned raster images with the reconstructed mesh, then projecting the color with a little software magic.


Granted, there is a small amount of visual distortion in the resulting reconstruction and texturizing of the mesh. I'm sure with a few dozen more images of this scene, along with more processing time, that would result in a more accurate volumetric representation of the scene. To achieve a higher quality texture map, a little more love needs to be used when parameterizing the raster images onto the mesh.
One thing to remember is that photogrammatically reconstructed surfaces have no inherent relation to scale. This can be corrected with a comparison to a known reference dimension. We could probably look up on Amazon the dimensions of the "Pocket Kanji Guide", and appropriately scale the data. In this instance, accuracy in scale isn't the main intent. If inserted dimensionally accurate references into the photo, rescaling should be reasonably accurate. Meshlab's default output unit is in millimeters.
Compare the result of our quick, admittedly low-quality reconstruction (using a dozen VGA-resolution images), versus one with hundreds of reference photos and processed overnight using expensive (but very good) software. These images are probably taken on something with better than VGA resolution.

A few limitations -
Since we're using visible-light techniques, we have to deal with optical restrictions. Reflections and shadowed surfaces are troublesome to reconstruct. Diffuse, even lighting conditions are optimal for photogrammetric reconstruction, so try taking pictures outside on a cloudy day. Lens choice is also important, with a 35-50 mm lens most closely approximating the human field of view with the least amount of distortion.
Objects scanned with photogrammetry techniques should typically remain still while capturing data. It's possible to assemble a camera rig with n cameras in various orientations around a common scene. Multiple instantaneous views could then be processed using these techniques.
The SIFT algorithm works best when applied on images with lots of orientable visible features, like repeating vertical and horizontal lines and contrasting color; not so well with objects like a plain flower vase where all sides appear the same.
The toolchain is painfully disjoint, requiring extensive domain knowledge and a mostly undocumented software stack to make sense of the subject. We have yet to attempt importing the resulting mesh into engineering software like Solidworks, which would require conversion of file type using yet another piece of software. We've used FreeCAD to convert the mesh to IGES format, but this can also be done with propietary software packages like GeoMagic. The conversion can be non-trivial and lossy, akin to making vectors from rasters.
A few benefits -
Apart from being a non-contact reconstruction method, photogrammetry lends itself well to scaling. Very small or very large objects can be reconstructed with similar ease. Your only limitation for mesh size is how much horsepower your workstation has. Meshlab / VisualSFM can also be configured to run on AWS cloud, which has options for choosing GPU heavy machines.
You can also grok crowdsourced images from Google, and use people's vacation photos of visiting the Coliseum in Rome, feeding the resulting data into VisualSFM with impressive results. Screen captures from videos? No problem. In fact, you could walk by your scan target with your cameraphone recording a high definition video of the target, and reconstruct these things later. Soon, this is a process that will happen on-the-fly.
Only recently has technology become affordable enough and accessible enough to whimsically perform these types of operations on a large data set like a complex, textured 3D object. Although Moore's law is tapering off, processor power continues to get cheaper and smaller. It's exciting to consider what will develop in the near future as people continue to discover more efficient algorithms, better sensors, and more creative applications.
What kinds of interesting things can you think of to use this technology for?
*VisualSFM, by Changchang Wu, is a closed source program developed from scratch. SiftGPU is Open sourced. The SIFT algorithm, by David Lowe, is patented in the US to the University of British Columbia. Meshlab is released using the GPL license.
The NEX comes with a number of new and exciting features, including a 'true' full-screen display without a notch, a retractable selfie-cam that pops up at the press of a button, an in-display fingerprint scanner, and a piezoelectric speaker like the original Mi Mix from Xiaomi. https://www.scscan.cc/
ReplyDeleteI like this post,And I figure that they having a great time to peruse this post,they might take a decent site to make an information,thanks for sharing it to me. scanning
ReplyDeletePleasant post. I see something harder on various web journals ordinary. It will dependably be animating to figure out how to peruse content from different journalists and practice a little at their store. You describe it within a very few and simple steps. I find difficulties in adjusting the measurement of the 3d scanning services Calgary, Alberta item. Surely will try again.
ReplyDeleteSocial insurance focuses, retail structures and stockroom are generally genuine instances of business land.VR for Real Estate
ReplyDeleteawesome site
ReplyDelete3D Printer Service in Bengaluru
3d scanner
best 3d pen
Hello I am so delighted I located your blog, I really located you by mistake, while I was watching on google for something else, Anyways I am here now and could just like to say thank for a tremendous post and a all round entertaining website. Please do keep up the great work. ShopVoChong24H
ReplyDeleteThis is my first time i visit here and I found so many interesting stuff in your blog especially it's discussion, thank you. CCTV Melbourne
ReplyDelete3D laser scanning is the process of collecting information about an object using laser light. A 3D laser scanner can collect the most accurate information. The collected information can be used for reverse engineering, 3D printing, or more. Best 3D laser scanning service Calgary, Alberta
ReplyDeleteFacing troubles with your Brother Printer? Receive quick solutions for every error and malfunction.
ReplyDeletebrother printer support
The information you shared was useful. You have brought up a very wonderful points , regards for the post.
ReplyDeletelexmark printer support | epson printer support
There are numerous instances of destinations on the Web today that compare to the initial three stages. The fourth stage is one that is just currently starting to develop. The four stages are: CAD modeling with SolidWorks
ReplyDeleteThe dummy security cameras help in alerting the miscreant and prevent crimes like real cameras. However, real cameras provide important evidence at the court when a crime is committed.Reolink not working
ReplyDeleteYou may stuck with various errors if you are using Lexmark printer, some of them being, Lexmark software not updated, Lexmark Printer drivers not updated, frequent paper jam issues or ink cartridge errors, printer not connecting to wireless network and many more. All these issues are well rectified by our Lexmark printer support.
ReplyDeleteWebroot.com/safe - Security is one of the considerable aspects nowadays, especially when it comes to the digital world. Almost all of our work has been accomplished through components of the digital world, and we do know that there are numerous harmful elements that reside in it. These elements always tend to acquire our personal data through their own developed gimmicks.
ReplyDeleteAfter study few of the articles on your blog nowadays, and i love your method of blogging. I tag it to my favorites net web site list and will be checking back soon. Please visit my web site too and let me recognize your thought. https://royalcbd.com/cbd-legal-status/
ReplyDelete
ReplyDeleteDragon Naturally Speaking Professional. Overview: Designed specifically for the legal industry, Nuance Dragon Legal Individual speech recognition software
dragon naturally speaking | dragon naturallyspeaking | nuance dragon | nuance dragon naturallyspeaking | naturally speaking
This Blog Content is very helpful For me and I have learned so many things with this blog.I must say you have to write more blogs like this kind of blog.
ReplyDeleteOffice.com/setup |
office.com/setup |
Office.com/setup |
Office.com/setup |
mcafee.com/activate |
mcafee.com/activate |
mcafee.com/activate |
mcafee.com/activate
Thanks for this useful information.
ReplyDeleteoffice.com/setup
office.com/setup
mcafee.com/activate
norton.com/setup
Collaborate for free with online versions of Microsoft Word, PowerPoint, Excel, and OneNote. Save documents, spreadsheets, and presentations online, in OneDrive. Share them with others and work together at the same time.
ReplyDeleteoffice.com/setup
www.office.com/setup 1.Go to office.com/setup for office setup.2.SignIn to your Microsoft Office Account.3.Find your Office Product Key.4.Enter your Microsoft Office Product Key.5.Download and Install Office.6.Run the Activation wizard.You are all done, Run Office Apps.
ReplyDeletehttps://www.ukofficeoffice.com/
www.office.com/setup
www.webroot.com/safe, Activate Your Webroot Safe setup at Webroot.com/safe as installing Webroot SecureAnywhere in Your PC. Download, install and activate webroot at www.webroot.com/activate.
ReplyDeletewww.Webroot.com/Safe
www.webroot.com/activate
Follow sling.com/activatethe instructions on your device to get an activation code. Your computer and device must both be connected to the internet to www.sling.com/activate." /> With a lot of people switching to stream TV and growing on the idea of on-demand content or binging the whole season altogether, the cable networks had to step-up their game. Bringing home Roku TV will suffice for all your entertainment needs. Sling TV offers its subscribers with on-demand shows, movies and DVD downloads for some shows and channels. Sling TV offers the perk of getting karaoke through the Sling TV app.
ReplyDeletewww.sling.com/activate
It is amazing post, i am really impressed of your post. Its really useful. Thank you for sharing this article.
ReplyDeletenorton.com/setup | www.norton.com/setup | norton.com/setup
nice post keep it up hp printer support toll free number
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDelete